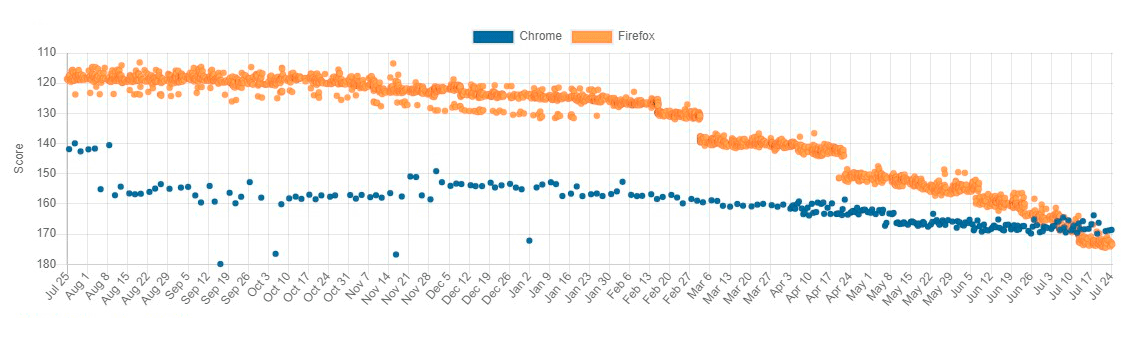
В июле 2023 года произошло важное событие — Firefox превзошёл Chrome в популярном тесте Speedometer, который измеряет скорость работы браузеров.
Были времена, когда Firefox считался медленным и неповоротливым браузером, потребляющим много памяти и в целом «тормозным». Когда появился Chrome, то некоторые пользователи перешли на него из-за лучшей производительности. Сейчас ситуация кардинально меняется.
Как Mozilla сумела добиться такого результата?
Оптимизация скорости
Разработчики Firefox долго и упорно работали над оптимизацией и устранением багов — и в конце концов эта работа дала эффект. Была установлена чёткая программа действий с измеримыми результатами.
В первую очередь Mozilla разработала и внедрила фреймворк Raptor для проведения автоматических тестов, чтобы измерять производительность своих продуктов — и интегрировала его в CI, то есть в стандартный процесс разработки и выпуска новых версий ПО. Другими словами, новые версии программ не выпускаются без предварительного бенчмарка. Автоматизацией тестов занимается отдельная группа девопсов PerfTest Team под руководством «шерифа по производительности» Дейва Ханта, опытного специалиста по автоматизации.
Два крупнейших скачка в производительности Firefox в марте-апреле 2023 года на графике связаны с двумя конкретными исправлениями: изменение обработки аттрибута autofocus в соответствии со спецификациями и динамическая настройка максимального размера «грязных» страниц в аллокаторе памяти mozjemalloc с увеличением этого размера для процессов с фоновым контентом.
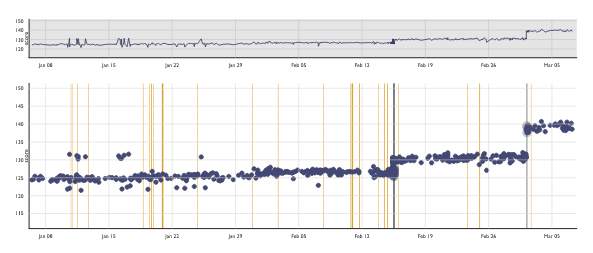
В принципе, можно нажать на каждую точку на графике — и посмотреть, что изменилось с этим коммитом. Например, внезапные скачки в производительности Chrome связывают с изменениями в инфраструктуре тестирования.
Результаты Firefox и Chrome в разных тестах на всех платформах в более наглядном виде показаны здесь:

Как видим, Speedometer — не единственный бенчмарк, в котором Firefox удалось опередить конкурента. Хотя по многим другим тестам впереди Chrome.
Фреймворк Raptor запускается в среде Browsertime (Node.js, Selenium WebDriver) на Firefox Desktop, Firefox Android GeckoView, Fenix, Chromium и Chrome. Судя по списку программ, Mozilla выбрала в качестве ориентира именно Chrome. Поэтому мы не можем сравнить их с остальными браузерами в данной среде. Только друг с другом.
Raptor поддерживает три типа тестов:
- тесты на загрузку страниц;
- стандартные бенчмарки;
- «сценарные» тесты, например, измерение энергопотребления, процессора и памяти.
Список «стандартных бенчмарков» (пункт 2) состоит из стандартных независимых тестов, включая Speedometer 3 (sp3), MotionMark и JetStream. Тесты на загрузку страниц измеряют реальное время загрузки и рендеринга популярных сайтов, таких как YouTube и Википедия.
- amazon
- bing-search
- buzzfeed
- cnn
- ebay
- espn
- expedia
- fandom
- google-docs
- google-mail
- google-search
- google-slides
- imdb
- imgur
- microsoft
- netflix
- nytimes
- office
- outlook
- paypal
- tumblr
- twitch
- wikia
- wikipedia
- yahoo-mail
- youtube
Настройки одного из тестов:
- alert on: fcp, loadtime, ContentfulSpeedIndex, PerceptualSpeedIndex, SpeedIndex, FirstVisualChange, LastVisualChange
- alert threshold: 2.0
- apps: firefox, chrome, chromium, safari, custom-car
- browser cycles: 25
- expected: pass
- gecko profile entries: 14000000
- gecko profile interval: 1
- lower is better: true
- page cycles: 25
- page timeout: 60000
- playback: mitmproxy
- playback pageset manifest: mitm7-linux-firefox-youtube.manifest
- playback version: 8.1.1
- secondary url: https://www.youtube.com/watch?v=JrdEMERq8MA
- test url: https://www.youtube.com
- type: pageload
- unit: ms
- use live sites: false
- Test Task:
В целом список тестов Raptor кажется максимально полным из того, что можно придумать для такой задачи. Это более объективная метрика, чем любой одиночный бенчмарк.
Примечание. В отдельных независимых тестах лучший результат по отдельным бенчмаркам могут показывать Edge, Safari или Opera. Так что звание «самого быстрого браузера» нельзя никому присудить однозначно, всё зависит от конкретного бенчмарка, версии браузера, включённых опций компиляции и флагов (настроек) браузера, а также платформы, на которой проводится тестирование (опции GPU-рендеринга, аппаратные функции CPU, настройки и версия ОС). Оптимальный вариант для пользователей — установить все интересующие браузеры на своём компьютере, запустить тесты на официальных сайтах (ссылки ниже) — и сравнить результаты в своей конкретной конфигурации. Вероятно, на macOS естественное преимущество получит Safari, а на Windows — Edge. Поскольку браузер и ОС в этих случаях разрабатывает одна компания (Apple и Microsoft, соответственно), она может применить некие общие системные оптимизации.
Chrome не сдаётся
Производительность можно измерять по-разному. В данный момент есть три основных бенчмарка для браузеров: Speedometer, MotionMark и JetStream.
В июне 2023 года разработчики Chrome заявили о достижении максимальных для себя результатов во всех трёх тестах. По их словам, чуть более чем за год результат Speedometer вырос с 300 (версия Chrome 101) до 491 (Chrome 116.0.5803.2 на M2 Macbook Air с включённым компилятором Maglev при сборке браузера).
Результат теста графической подсистемы MotionMark почти утроился с начала 2023 года до 4821,30 (Chrome M115.0.5773.4 на 13” M2 Macbook Pro).
Бенчмарк JetStream (JavaScript и WebAssembly, продвинутые веб-приложения) благодаря внедрению Maglev показал рост до 330,939 (Chrome 116.0.5803.2 на M2 Macbook Air с Maglev). Каков был прежний результат, не сообщается.
Обратим внимание, что тесты Google проводились на сборке Chrome с новым промежуточным JIT-компилятором Maglev, который «позволяет генерировать эффективный машинный код для всех релевантных функций в течение сотых долей секунды». По внутренним тестам, Maglev для движка V8 улучшил результат Jetstream на 7,5%, а Speedometer — на 5%.
На первый взгляд, результаты Google не очень сходятся с графиками Raptor, как будто они используют разные версии браузеров и бенчмарков (например, Speedometer 3 сильно отличается от Speedometer 2). Вопрос в том, какие тесты более соответствуют фактическому опыту пользователей.
Так или иначе, но соревнование разработчиков Firefox и Chrome на поле оптимизации можно только приветствовать.
Риск монополии
Некоторые специалисты считают, что нельзя допустить монополии Google Chrome на браузерном рынке на фоне того, часто всё больше сторонних браузеров переходят на движок и кодовую базу Chrome. В то же время аудитория Firefox продолжает снижаться. По статистике Mozilla, аудитория Firefox сократилась на 60 млн за четыре года, что составляет 24% аудитории (с пиковых 252 млн в 2019 году до 191 млн в июле 2023-го).

В такой ситуации появляются риски, что веб-сайты начнут разрабатывать в соответствии со стандартами, которые поддерживаются в Chrome, а не по официальным стандартам W3C. Недавняя история с удалением формата JPEG-XL из Chrome в октябре 2022 года стала хорошим индикатором нынешнего положения дел. Если бы не неожиданная поддержка со стороны Apple, этот качественный формат сжатия графики рисковал забвением. Однако на конференции WWDC23 компания Apple объявила о поддержке JPEG-XL во всех своих продуктах, включая Safari 17, новые версии iOS, iPadOS, macOS, watchOS и visionOS. Разработчики JPEG-XL с иронией восприняли тот факт, что первым браузером с поддержкой JPEG-XL стал Safari. Кто мог такое представить для формата, созданного при участии Google?
Монополия реально угрожает разработке новых форматов и перспективных технологий, которые могут оказаться на обочине истории по прихоти монополиста. Поэтому конкуренция со стороны Firefox очень важна для рынка браузеров, ведь Gecko по сути остался единственным независимым движком для рендеринга веб-страниц, не считая экспериментальных проектов Quantum и Servo от той же Mozilla.
ссылка на оригинал статьи https://habr.com/ru/articles/752862/

")
 — множество всех значений соответствующего атрибута (полная компонента) и
— множество всех значений соответствующего атрибута (полная компонента) и  (пустая компонента).
(пустая компонента).![\quad \quad M_1[R_2R_3] = [\{L,E\} \quad \{L,T\}]](https://habrastorage.org/getpro/habr/formulas/f/ff/ff4/ff43816fb63eae81be31cb65107521f6.svg) и
и![\quad \quad M_2[R_1R_2] = [\{L,T\} \quad \{L,E\}]](https://habrastorage.org/getpro/habr/formulas/0/09/091/091d10ea6f4cc3e96a0cd017015ac718.svg) .
.![\overline{M_2}[R_1R_2] = \begin{bmatrix} \{E\} & * \\ * & \{T\} \end{bmatrix}](https://habrastorage.org/getpro/habr/formulas/e/e9/e94/e947734449dcb85cf52c2c3ac29d38eb.svg)
![M_1[R_2R_3] \cap_G \overline{M_2}[ R_1R_2] = [\ast \quad \{L,E\} \quad \{L,T\}] \cap \begin {bmatrix} \{E\} & * & *\\ * & \{T\} & * \end{bmatrix} = [\{E\}\quad \{L,E\} \quad \{L,T\}].](https://habrastorage.org/getpro/habr/formulas/c/c9/c99/c9935457a072349bb3e9c60153d9e393.svg)
 ) и точная верхняя грань (обозначается sup или
) и точная верхняя грань (обозначается sup или  ). В общем случае эти операции выполняются для всех пар элементов решетки, но бывают другие варианты (нам они не понадобятся). В отличие от просто верхней (или нижней) грани точная верхняя (нижняя) грань дает в результате единственный элемент решетки.
). В общем случае эти операции выполняются для всех пар элементов решетки, но бывают другие варианты (нам они не понадобятся). В отличие от просто верхней (или нижней) грани точная верхняя (нижняя) грань дает в результате единственный элемент решетки. (обычно отношение порядка в общем случае для у-множеств обозначается
(обычно отношение порядка в общем случае для у-множеств обозначается  , но мы этот знак будем здесь использовать для отношения «меньше или равно» для обычных чисел). Пусть даны числовые n-кортежи
, но мы этот знак будем здесь использовать для отношения «меньше или равно» для обычных чисел). Пусть даны числовые n-кортежи  и
и  . Определим для них отношение порядка и операции.
. Определим для них отношение порядка и операции. подтверждается, если и только если
подтверждается, если и только если  для всех
для всех  . В противном случае n-кортежи не сравнимы.
. В противном случае n-кортежи не сравнимы.



 :
:
 расположен после атрибута
расположен после атрибута  лишь при условии
лишь при условии  .
. . Тогда, если использовать схему отношения, получим следующую запись этого числа с помощью числовых кортежей:
. Тогда, если использовать схему отношения, получим следующую запись этого числа с помощью числовых кортежей:](https://habrastorage.org/getpro/habr/formulas/a/ab/abb/abbd62ffee233b876e6d4fd0f276a22e.svg) (после схемы отношения числа записывается числовой кортеж, с помощью которого это число можно выразить в позиционной системе счисления).
(после схемы отношения числа записывается числовой кортеж, с помощью которого это число можно выразить в позиционной системе счисления)..](https://habrastorage.org/getpro/habr/formulas/2/2d/2d2/2d250a07f443803e44299c44747b9e85.svg)
![[P_1P_5]](https://habrastorage.org/getpro/habr/formulas/a/ab/abc/abc4103d302dc67f585ba8b2b7df8945.svg) , но и, допустим, в схеме отношения
, но и, допустим, в схеме отношения ![[P_1P_2P_4P_5]](https://habrastorage.org/getpro/habr/formulas/8/89/894/89498f889bd43d93180855005dc8e939.svg) :
:](https://habrastorage.org/getpro/habr/formulas/a/a0/a06/a06809372ea3d6d37b7f6329a7ac4dd9.svg) .
.](https://habrastorage.org/getpro/habr/formulas/f/fe/fea/feaaf611f5528f0d77095462465dac59.svg) .
.](https://habrastorage.org/getpro/habr/formulas/d/db/dbd/dbd4d972571043e1821474b2e464367f.svg) .
.](https://habrastorage.org/getpro/habr/formulas/4/41/412/4121d90ff7c243796fcf79626c09c088.svg) .
.](https://habrastorage.org/getpro/habr/formulas/3/30/301/301a9ca1a60cf51a5c6aa2eca2977528.svg) .
. \Rightarrow 2^3 \cdot 3^3 \cdot 5 \cdot 7^2 \cdot 11 = 582120](https://habrastorage.org/getpro/habr/formulas/0/02/02c/02c4783993a1a98dac2ed21cd718efb9.svg) .
. ): после добавления недостающих фиктивных атрибутов в числовых кортежах вычисляются суммы соответствующих компонент. Эта операция соответствует произведению исходных чисел.
): после добавления недостающих фиктивных атрибутов в числовых кортежах вычисляются суммы соответствующих компонент. Эта операция соответствует произведению исходных чисел. ): после добавления недостающих фиктивных атрибутов в числовых кортежах вычисляются разности соответствующих компонент. Эта операция соответствует делению исходных чисел.
): после добавления недостающих фиктивных атрибутов в числовых кортежах вычисляются разности соответствующих компонент. Эта операция соответствует делению исходных чисел.
 \Rightarrow \frac {3 \cdot 5 \cdot 11} {2^3 \cdot 7^2}= \frac {165} {392}.](https://habrastorage.org/getpro/habr/formulas/1/15/157/1572d2254a1eb3203c5cdea48bd26fd3.svg)
 ): если числовые кортежи содержат только неотрицательные целые числа, то тут все понятно – мы вычисляем наибольший общий делитель (НОД) двух исходных чисел. А если в числовых кортежах содержатся отрицательные целые числа, тогда что? Нетрудно доказать, что это наибольшее рациональное число, результатом деления на которое исходных рациональных чисел, получатся целые числа.
): если числовые кортежи содержат только неотрицательные целые числа, то тут все понятно – мы вычисляем наибольший общий делитель (НОД) двух исходных чисел. А если в числовых кортежах содержатся отрицательные целые числа, тогда что? Нетрудно доказать, что это наибольшее рациональное число, результатом деления на которое исходных рациональных чисел, получатся целые числа. ): для числовых кортежей с неотрицательными целыми числами вычисляется наименьшее общее кратное (НОК) исходных чисел.
): для числовых кортежей с неотрицательными целыми числами вычисляется наименьшее общее кратное (НОК) исходных чисел. . Тогда четное целое значение соответствующего элемента в числовом кортеже означает, что мы имеем дело с положительными исходными числами, если же соответствующее число в кортеже целое нечетное, то исходное число отрицательное.
. Тогда четное целое значение соответствующего элемента в числовом кортеже означает, что мы имеем дело с положительными исходными числами, если же соответствующее число в кортеже целое нечетное, то исходное число отрицательное. другие значения в числовых кортежах? На ум приходит число
другие значения в числовых кортежах? На ум приходит число  В этом случае нашему взору откроется мнимое число.
В этом случае нашему взору откроется мнимое число. и
и  , соответственно
, соответственно  и
и  .
. ). Если в числовых кортежах содержатся только неотрицательные целые числа, то это отношение соответствует известному отношению делимости (
). Если в числовых кортежах содержатся только неотрицательные целые числа, то это отношение соответствует известному отношению делимости ( ) для множества положительных целых чисел. Если числовые кортежи содержат отрицательные целые числа, то исходные числа могут быть и дробями, но при этом если
) для множества положительных целых чисел. Если числовые кортежи содержат отрицательные целые числа, то исходные числа могут быть и дробями, но при этом если  , то можно легко доказать, что результатом деления
, то можно легко доказать, что результатом деления  будет целое число. Это обстоятельство позволяет ввести новое отношение порядка по делимости не только для целых, но и для рациональных чисел (
будет целое число. Это обстоятельство позволяет ввести новое отношение порядка по делимости не только для целых, но и для рациональных чисел ( ). А вот как интерпретируются случаи, когда в числовых кортежах содержатся несократимые дроби, пока непонятно.
). А вот как интерпретируются случаи, когда в числовых кортежах содержатся несократимые дроби, пока непонятно. . Это можно легко доказать, используя свойство неубывания показательной функции
. Это можно легко доказать, используя свойство неубывания показательной функции  , где
, где  — неотрицательное действительное число.
— неотрицательное действительное число.  вычислительной сложности. Эта оценка существенно меньше оценок вычислительной сложности
вычислительной сложности. Эта оценка существенно меньше оценок вычислительной сложности ](https://habrastorage.org/getpro/habr/formulas/c/cd/cd3/cd3df8b2cc8dfca0626ebb828f215e91.svg) и соответствующего ей числа
и соответствующего ей числа  , выраженного в традиционной системе счисления.
, выраженного в традиционной системе счисления.](https://habrastorage.org/getpro/habr/formulas/5/56/565/5657139d6b611bedfd8489aa0cfb5b1f.svg)